








How Does the Genetic Code Work in NEET Biology?
The genetic code is a fundamental concept in Biology, especially important for NEET aspirants. It explains how genetic information stored in DNA is translated into proteins - the building blocks of life. Understanding the genetic code gives students the foundation to grasp molecular genetics and gene expression, which are frequently tested in NEET exams. Mastering this topic not only clarifies basic mechanisms of life, but also strengthens your overall conceptual understanding for the exam.
What is the Genetic Code?
The genetic code is a set of rules by which the information encoded in genetic material (DNA or RNA) is translated into proteins by living cells. It determines how sequences of the four nucleotide bases (adenine, thymine/uracil, cytosine, and guanine) in mRNA are converted into the amino acid sequence of a protein. For NEET students, knowing what the genetic code is and how it works is essential for understanding gene function, protein synthesis, and mutations.
Core Ideas and Fundamentals of the Genetic Code
Triplet Code
The genetic code is read in triplets of nucleotides called codons. Each codon codes for one amino acid. Since there are four different bases and three bases per codon, there are 43 = 64 possible codons, but only 20 standard amino acids. This redundancy is known as degeneracy of the code.
Codons and Amino Acids
A codon is a sequence of three nucleotides in mRNA that corresponds to a specific amino acid or a stop signal during translation. Most amino acids are encoded by more than one codon, making the genetic code degenerate, but never ambiguous - each codon codes for only one specific amino acid.
Start and Stop Codons
Among the 64 possible codons, one (AUG) serves as the start codon, signaling where protein synthesis should begin. Three codons (UAA, UAG, UGA) are stop codons, which signal the end of protein synthesis.
Universality of the Genetic Code
The genetic code is nearly universal across all living organisms, from bacteria to humans, with only a few rare exceptions. This highlights the common evolutionary origin of all life forms, a key aspect often discussed in NEET questions.
Important Sub-concepts Related to the Genetic Code
Degeneracy of the Code
Degeneracy means that most amino acids have more than one codon. For example, leucine is coded by six different codons. This feature provides a buffer against mutations - if a base in a codon changes, the amino acid may still stay the same.
Non-overlapping Nature
The code is non-overlapping, meaning each nucleotide is part of only one codon. This ensures the correct reading frame is maintained during translation, preventing mixing up of amino acids in proteins.
Comma-less/Continuous
The genetic code is comma-less, which means codons are read one after another without any commas or gaps. Reading begins at a start codon and continues until a stop codon is reached.
Wobble Hypothesis
The wobble hypothesis explains that the third position of a codon can often vary without changing the amino acid it codes for. This explains much of the redundancy (degeneracy) in the genetic code and is an important aspect tested in NEET exams.
Genetic Code Table and Codon Assignments
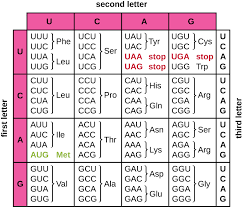
The image above illustrates the genetic code table, showing each mRNA codon and its corresponding amino acid. This table is crucial for solving NEET problems involving codon identification, mutation consequences, and decoding amino acid sequences from mRNA.
Rules and Principles of the Genetic Code
- The genetic code is universal (with minor exceptions).
- It is degenerate - multiple codons can code for the same amino acid.
- It is non-overlapping - each nucleotide is read only once.
- It is comma-less/continuous - codons are read in a sequence without gaps.
- There are three stop codons (UAA, UAG, UGA) and one start codon (AUG).
Characteristics and Limitations
Key Features
- Specificity - Each codon specifies only one amino acid.
- Redundancy - More codons than amino acids, reducing mutation effects.
- Universality - Functions nearly the same across all life forms.
- No ambiguity - Codons never code for more than one amino acid.
Limitations
- Rare exceptions to universality exist in some mitochondrial and protozoan codes.
- Cannot always predict impact of mutations (silent, missense, nonsense) without context.
Why is the Genetic Code Important for NEET?
Questions about the genetic code are common in NEET due to its central role in gene expression and protein synthesis. Mastery of this concept supports understanding of related topics such as transcription, translation, mutations, gene regulation, and biotechnology. Interpreting codons, predicting effects of mutations, and understanding genetic diseases all rely on a clear grasp of the genetic code. A strong foundation here makes complex molecular biology questions much easier to tackle in the exam.
How to Study the Genetic Code Effectively for NEET
- Understand the triplet nature of codons and their assignment to amino acids using the genetic code table.
- Practice decoding mRNA sequences into amino acid sequences.
- Memorize start and stop codons, and understand their roles in protein synthesis.
- Revise definitions and principles – degeneracy, universality, non-overlapping code.
- Use diagrams and tables during revision for better recall and understanding.
- Solve NEET-level MCQs on codon identification, mutations, and translation errors.
- Regularly revise quick facts and commonly tested exceptions.
Common Mistakes Students Make in the Genetic Code
- Confusing DNA codons (triplets) with mRNA codons (remember: transcription replaces thymine with uracil in mRNA).
- Misinterpreting the start and stop codons.
- Forgetting the degeneracy (multiple codons for one amino acid) and assigning wrong amino acids to codons.
- Incorrectly reading the genetic code frame, leading to mistakes in translation.
- Assuming codons can overlap or skipping nucleotides (frame shift mistakes).
Quick Revision Points: Genetic Code
- Genetic code is a triplet code - 3 nucleotides (codon) code for 1 amino acid.
- There are 64 codons but only 20 amino acids - many amino acids have multiple codons.
- AUG is the start codon; UAA, UAG, and UGA are stop codons.
- The code is non-overlapping, comma-less, and nearly universal.
- Degeneracy helps minimize effects of some mutations.
- Practice reading the genetic code table to quickly assign amino acids to codons.
- Be cautious of exceptions such as mitochondrial codes or rare start codons.
FAQs on Genetic Code in NEET Biology: Complete Guide
1. What is the genetic code in Biology?
The genetic code is the set of rules by which information encoded in DNA or RNA nucleotide sequences is translated into proteins by living cells. For NEET students, understanding genetic code means knowing how genetic information is converted into the sequence of amino acids in proteins.
- Each codon is a sequence of three nucleotides (triplet).
- Codons specify which amino acid will be added next during protein synthesis.
- The code is universal, degenerate (redundant), and non-overlapping.
2. What are the key features of the genetic code?
The genetic code has several important features that help maintain accuracy in protein synthesis, a critical NEET concept:
- Triplet Nature: Each codon consists of three nucleotides.
- Degeneracy: Most amino acids are encoded by more than one codon.
- Non-overlapping: Codons are read one after another without sharing bases.
- Commaless: No punctuation marks between codons.
- Universal: Same codon codes for the same amino acid in almost all organisms.
- Non-ambiguous: Each codon specifies only one amino acid.
3. Why is the genetic code called 'degenerate'?
The genetic code is called degenerate because most amino acids are specified by more than one codon.
- For example, Leucine is coded by six different codons.
- This redundancy helps protect against mutations, as a change in the third base sometimes still codes for the same amino acid.
4. What is a codon and how does it function?
A codon is a sequence of three nucleotides on mRNA that code for a specific amino acid or signal the end of protein synthesis.
- Coding codons correspond to the 20 standard amino acids.
- Three codons act as stop signals (UAA, UAG, UGA).
- One codon (AUG) acts as the start codon as well as for Methionine.
5. What is the importance of the start and stop codons?
Start and stop codons are essential for accurate initiation and termination of protein synthesis.
- Start Codon (AUG): Signals the start of translation; codes for Methionine.
- Stop Codons (UAA, UAG, UGA): Signal the end of translation, ensuring proper protein length.
6. Why is the genetic code considered universal?
The genetic code is considered universal because almost all living organisms use the same codons to specify amino acids.
- This means a gene from one species can be expressed in another (e.g., bacterial production of human insulin).
- Universality is a key topic in NEET Biology, demonstrating evolutionary conservation.
7. Who deciphered the genetic code?
The genetic code was deciphered primarily by Har Gobind Khorana, Marshall Nirenberg, and Robert Holley.
- Their experiments in the 1960s identified which codons correspond to which amino acids.
- For NEET, knowing these scientists and their contributions is important for exam questions.
8. What is the significance of frame shift mutations in relation to the genetic code?
Frame shift mutations occur when nucleotides are inserted or deleted, disrupting the triplet reading frame of the genetic code.
- This often leads to incorrect amino acid sequences and non-functional proteins.
- NEET syllabus highlights frame shift mutations as a cause of genetic disorders.
9. How many codons are present in the genetic code and how many code for amino acids?
The genetic code consists of 64 codons in total.
- Of these, 61 codons code for the 20 standard amino acids.
- The remaining 3 codons function as stop signals.
10. Explain why the genetic code is described as non-overlapping and commaless.
The genetic code is described as non-overlapping because each nucleotide is part of only one codon and not shared with adjacent codons. It is commaless as there are no gaps or punctuation between codons.
- Reading occurs continuously, three bases at a time, without overlap or stops in between.
- This property ensures accurate translation of genetic information into proteins, which is crucial for NEET exams.
11. What are the exceptions to the universality of genetic code?
Exceptions to the universality of the genetic code are found in some mitochondrial DNA and certain unicellular organisms.
- For example, UGA codes for tryptophan in human mitochondria instead of acting as a stop codon.
- Such exceptions are rare but mentioned in NEET-level books.
12. What is meant by the statement – 'Genetic code is non-ambiguous'?
The genetic code is non-ambiguous because each codon codes for only one specific amino acid.
- This minimizes confusion during protein synthesis and is an important exam concept for NEET students.